Chapter 01 – Pure Functions: Side Effects & Immutability
Introduction
As I mentioned in the Introduction, pure functions are pretty straightforward and adhere to three simple rules:
- They only operate on data passed into them.
- They don’t have any side effects like changing state outside of their immediate scope (this includes reading, writing, logging, etc.).
- They should follow referential transparency (aka be deterministic).
Likewise, the basic idea of immutability was also covered in the introduction and can be summed up as, “a variable, once created, cannot be changed.” As we also saw, this can get a little tricky with JS but as long as we know the rules, we can safely play the game!
Side note: Immutability is not explicitly covered in its own section but rather it is implied and demonstrated throughout this chapter.
Piggybacking off the idea of declarative programming are the requirements of pure functions and no side effects. When you consider the idea of abstracting away things like classes and loops and replacing them with functions, the obvious concern arises: how do I know that the functions I’m using are as error-proof as possible…especially if I wrote them?
Well, this is where the idea of pure functions and no side effects comes in. According to Atencio, pure functions:
- … depend only on the input provided and not on any hidden or external state that may change during its evaluation or between calls.
- …don’t inflict changes beyond their scope, such as modifying a global object or a parameter passed by reference.
Combine this with Uncle Martin’s advice on functions:
- They should be small…like, very small.
- They should do exactly one thing.
- They should have as few arguments as possible.
- They should have no side effects.
- They should not have flag arguments that make a function have two internal paths.
In a very concise nutshell, a pure function, when given the same input, will always produce the same output (deterministic). It doesn’t rely on variables outside of its scope and it doesn’t change any passed-in arguments, global variables, or any kind of state outside of its scope.
Now, taking this advice to its logical end doesn’t lead us to a very helpful place; especially in the world of web software engineering in JS. Here are a few things that you cannot do if your code is strictly pure:
- No changing the value of a variable, property, or data structure globally.
- No changing the value of a function’s argument.
- No writing to a database.
- No exception throwing if it will bubble out of the function it’s thrown in.
- No console logging or writing to the DOM.
- No querying the DOM, cookies, or local storage.
Side Effects
All of these operations would make a function impure. They would also effectively prevent you from writing anything useful in the web space :/. Don’t worry about this obvious problem just yet. Let’s take a look at some examples of an impure function with side effects just to be sure we understand what’s going on.
Impure
// Create a new person
const person = {
name: "Joe",
age: 23,
address: "1234 Main St."
}
// Function to update the age the passed in person
function updateAge(person, newAge) {
person.age = newAge;
return person;
}
// Update the person's age
const updatedPerson = updateAge(person, 50);
// updatedPerson.age -> 50
// but...
// person.age -> 50 too!!! Pure
// Create a new person
const person = {
name: "Joe",
age: 23,
address: "1234 Main St."
}
// Function to update the age the passed in person
function updateAge(person, newAge) {
const localPerson = Object.assign({}, person);
localPerson.age = newAge;
return localPerson;
}
// Update the person's age
const updatedPerson = updateAge(person, 50);
// updatedPerson.age -> 50
// and
// person.age -> 23...that's more like it. This example demonstrates a few weird properties of JS that make functional programming a bit odd. Depending on the type of variable passed into a function, it can be passed in by reference or by value. JS primitives (undefined, null, boolean, string, and number) are passed in by value while objects (including arrays) are passed by reference. This means that if we change a passed-in object’s properties within our function, it’s changing the object outside of the function. In the impure example, we can see that we’re violating Atencio’s rule #2 by modifying a passed-in variable (person.age). In the pure example, we’re using Object.assign() to shallow clone the person parameter thus making a locally-scoped version that we can safely modify and return.
Preventing Side Effects
In most NodeJS and front-end web applications, preventing function side effects comes down to:
- Cloning passed-in objects and arrays.
- You’re only using constants and Object.freeze() from here on out.
- Not affecting system state by pulling data in or pushing data out.
Cloning Passed-In Objects and Arrays
In the code example above, we prevented a side effect by shallow cloning the person parameter to prevent an update to the passed-by-reference object. This works fine for objects that are one level deep but for deeply nested objects, there are different strategies to use.
JSON.parse(JSON.stringify(testJSON))
or using the awesome lodash library:
_.cloneDeep(testJSON)
As a side note, I was curious which of these had better performance so I ran a little test with each. The tests ran each method 10,000 times on a 551 byte JSON structure and ended up with the following results:
➤ node clone.js
stringify: 44.120ms
cloneDeep: 48.177ms
As we can see, the native JSON stringify->parse is slightly more performant.
// Time stringify
console.time('stringify');
for (let i = 0; i < limit; i++) {
const deepClone = JSON.parse(JSON.stringify(testJSON));
}
console.timeEnd('stringify'); // Time cloneDeep
console.time('cloneDeep');
for (let i = 0; i < limit; i++) {
const deepClone = _.cloneDeep(testJSON);
}
console.timeEnd('cloneDeep'); Cloning an array is similar to an object, at least in terms of behavior. Using the spread operator is a quick way to shallow clone an array but will ultimately suffer from the same object reference problem that objects do:
// Mixed value array
const myarray = [5, "asdf", {deep: {object: "value"}}];
// User spread to shallow clone it
const arrayClone = [...myarray];
// Change a basic element
myarray[0] = 10;
// Change an array's object
myarray[2].deep.object = "yoyo";
console.log(myarray, arrayClone);
// Output: [ 10, 'asdf', { deep: { object: 'yoyo' } } ] [ 5, 'asdf', { deep: { object: 'yoyo' } } ] As we can see, changing the first element works as expected but changing the deep object’s value updates the cloned “arrayClone[2].deep.object” which is no good. Thankfully, the same cloning process for objects outlined above works with arrays too.
Not Affecting System State
This is where things get a little more unrealistic from a web software engineering perspective. State changes, user input, HTTP requests, DB access, DOM updates, etc. are all the fundamental points of using the web. If we can’t do these in our programs then what’s the point? Oddly enough, I haven’t seen this aspect of functional programming addressed much in the myriad of Medium and blog posts that have jumped on the functional programming in JS bandwagon. As such, I’m going to stick my neck out a bit here and propose some possible solutions for addressing this problem while still attempting to be as functional as possible.
The short of it is, yes, you can code functions that affect system state but you should:
- Mark them as such.
- Keep them abstracted/separated from core business logic.
- Contextualize your code so that pure and impure functions play nicely together.
From a NodeJS perspective where you might be writing server-side code, this is a bit easier as you can architect your project to logically separate pure and impure functions. This can be done through modules and file structure decisions. This will be demonstrated in the following section.
However, on the front end, this becomes a little harder as you are generally coding within a mainstream framework. These days that generally means React, Vue, or Angular. All modern incarnations of these frameworks are component-based and can use a global application state that may not be persistent as well as some kind of prop-passing mechanism to pass data into and emit data out of each component. Both are, fundamentally, ways to access and possibly mutate a higher-level state. The difference here is in context and that context is critical to coding functionally.
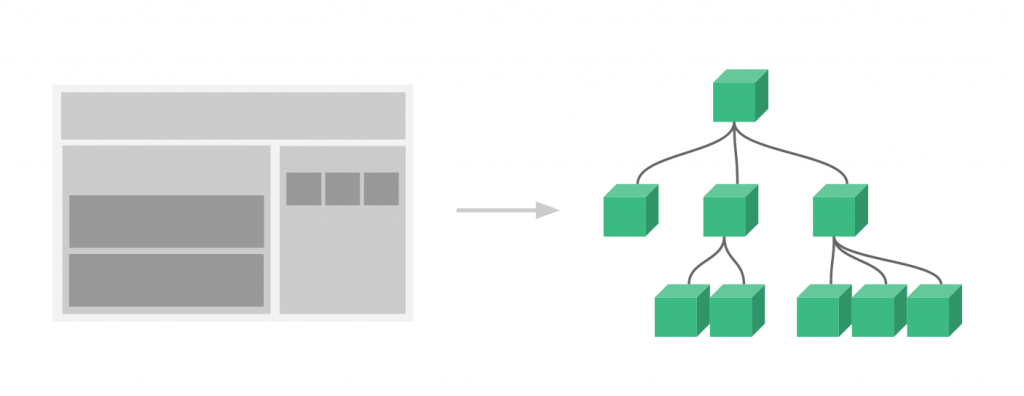
In case you are not familiar with component architecture, the above image is how a page component hierarchy might be laid out. Given a page of a website or web application, each section is broken out into components that when combined, constitute a page of the application.
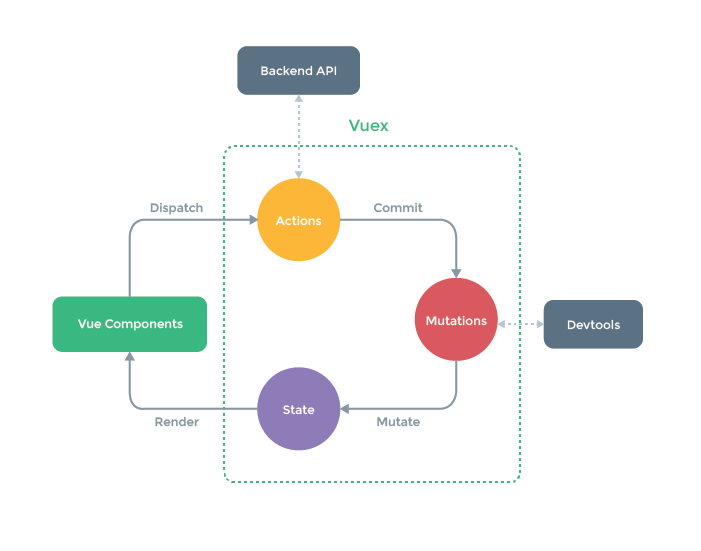
The above diagram is how Vuex, a state/store management library for the Vue frontend framework operates. It allows engineers to maintain a state that is global to all components regardless of the component hierarchy. Every component can access the state through this mechanism as well as make updates to that state.
Alternatively, components can pass and emit data through the properties or “props” of a component. When calling a component, you effectively pass in data, much like parameters into a function, and also specify other functions, at the parent component level, to be triggered when data is emitted or passed out of the component (kind of sort of like a function’s return…but not really).
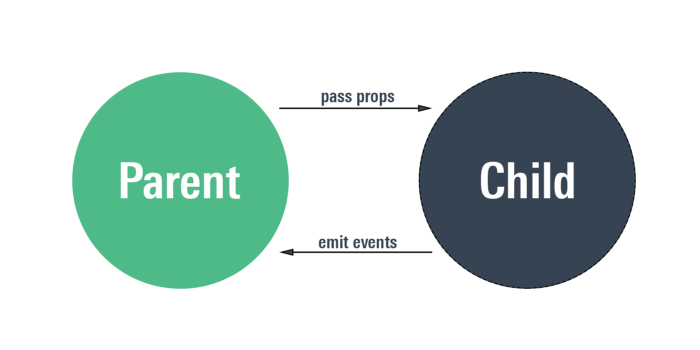
I mean, the above diagram kind of looks like a function. Data goes in, data comes out. The key difference here is that you can pass in multiple props and the child component can emit multiple pieces of data and has control over what and when an emit happens is entirely dependent on the internal workings of the child component. Nothing is strictly enforced by default.
With this general background, let’s move into some examples and recommendations on how to code as functionally as possible while still being realistic.
Using Pure Functions in an Impure World
In the above section, I recommended three ways that you could somewhat safely write state-altering code in a mostly functional way. Let’s dive into these and see how we can apply them. The biggest thing to keep in mind is that we’re clearly not going to meet any of these criteria but rather our goal is to get as close as possible.
Note: VueJS has the concept of a functional component which according to the docs is useful as a component wrapper. We won’t be covering that here.
Mark Them as Such
This seems obvious but implementing some kind of marker in the function name that signified that the function is not pure can help engineers know what they might be dealing with. I’ve seen this done to mark dangerous or private functions in classes (primarily PHP) and I don’t see why it wouldn’t work here. I kind of like appending an underscore “_” to the function name but whatever works for you.
function updateUserAge(user, age) {
const updatedUser = _.cloneDeep(user);
updatedUser.age = age;
return updatedUser;
}
// Impure function
async function saveUser_(user) {
return DB.saveUser(user);
}
// Primary business logic
await saveUser_(updateUserAge(currentUser, 39)); Abstract Them from Core Business Logic
This probably stands to reason but impure functions should be abstracted into separate libraries and kept away from core business logic. For instance, in a NodeJS API server like ExpressJS where you are given extensive liberties in how you architect your application, you have to be careful in how your modules and endpoints interact. The example below is a very basic “Hello World” ExpressJS example that listens to one endpoint and responds with text.
const express = require('express')
const app = express()
const port = 3000
app.get('/', (req, res) => {
Log.
res.send('Hello World!')
})
app.listen(port, () => {
console.log(`Example app listening at http://localhost:${port}`)
}) Example from https://expressjs.com/en/starter/hello-world.html
Let’s build this out a little to a more practical example:
// app.js
const express = require('express');
const app = express();
const port = 3000;
import Home from './routes/Home';
app.get('/', Home)
app.listen(port, () => {
console.log(`Example app listening at http://localhost:${port}`)
}) In our app.js file above, we still have the “/” route but we’ve abstracted it into a route module. Let’s take a look at what’s happening there. I’ve built it up a bit so that it’s doing a little more than just responding with text for our example.
// ./routes/Home.js file
import _ from 'lodash';
import Logger from "/libs/Logger";
import DB from "/libs/DB";
async function HomeRoute(req, res) {
// Clone objects to avoid side effects
const localReq = _.cloneDeep(req);
const localRes = _.cloneDeep(res);
//Log the hit using a local function marked as impure.
logHit_(req.url);
//Query the Db for page data
const pageData = await getHomePageData_(req.url);
// Return the response.
return returnResponse_(pageData.data);
}
function logHit_(url){
Logger.log(url);
}
function getHomePageData_(url){
return DB.get(url).catch((err)=>{
Logger.error(err);
});
}
function returnResponse_(payload) {
return res.send(payload);
}
export default HomeRoute; As we can see from the refactored example, the “HomeRoute()” function is the primary export of the module. The first thing we do is clone deep our passed-in objects since we know those are passed in by reference so we need to be safe here. Next, we want to log the hit to the homepage and since this is a side-effect-producing behavior, we abstract it out into a separate function using our spiffy trailing “_” to signify that the function is impure. Then, we need to get the page data from the database so, again, since that’s a side-effect producing request, we abstract it into “getHomePageData_().” Finally, we need to return the response using the “req.send()” but as we’re already familiar with it, we abstract this too. This breakdown keeps the main business logic function “HomeRoute” as pure as we can while also abstracting out behaviors to be more manageable. What we don’t necessarily see is the contents of the Logger and DB library files but they would behave similarly though likely less so simply because their sole purpose is to be side-effect producing.
Contextualize Your Code
Shifting gears to front-end applications, one of the practical ways to play nicely with pure and impure functions is to contextualize the code you are working in. A prime example of this is the component-based architecture of modern front-end applications.
The only way we can seemingly approach this functionally is to contextualize functional programming principles to the task at hand. As I mentioned in Chapter 00, it’s best to approach this from the perspective of layers. In pure functional programming, your level of analysis is the function. When dealing with something as interconnected as a component-based web application, that level of analysis should first be at the component level itself and then within the individual functions in the component.
As with Uncle Martin’s #1 rule for functions (they should only do one thing), we can borrow that idea here and argue that a component should really only do one thing and do it well. Now, depending on where said component is in the hierarchy of a page, that (mostly) one thing might be simply rendering child components or it could be handling HTTP requests of emitted data. This is also quite a decent gauge for knowing when a component is doing too much and might need to be broken up into multiple components. The point is that limiting the functionality of a component helps us code more functionally. Note that I mean this more from a logic perspective vs a display perspective in that component actions should be limited, not necessarily what they render.
So here are some guidelines we can follow to get frontend components looking like how we want them to:
Application State: We can’t avoid the use of application state but let’s try to keep any kind of state access within the component lifecycle hooks vs all over the component. This will at least help us limit the scope of any state-related problems we might encounter. Additionally, we should try to limit logic within lower-level components that create more than one pathway through the component. The following component template has display logic dependent on state. This should ideally be changed to be prop-dependent and should apply to logic in the lifecycle hooks as well.
// What not to do
<template>
<div>
<div v-if="$state.store.showToDos">
...
</div>
<div v-else>
...
</div>
</div>
</template> // A better alternative
<template>
<div>
<ToDos v-if="showToDos"></ToDos>
<AnotherComponent v-else></AnotherComponent>
</div>
</template>
<script>
...
props: [showToDos]
...
</script> Side Effects: For components that do the necessities like accessing/writing to local storage or making AJAX requests…things with clear side effects, we should try to keep this logic abstracted into separate libraries as much as possible and also keep the use of those libraries as high as we can in the component hierarchy. Components should try to use props and emit, as the first-line option and only if that is too impractical should they trigger side effects on their own.
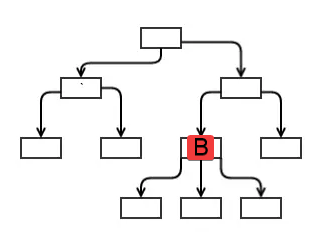
Having said that, engineers should also try their best to keep their apps shallow enough to avoid having to pass data through too many layers. Ideally, any side effects would be limited to what I call the “feature parent” component. If we take the image below to be a four-level hierarchy of a web application and component “B” is, say, the content footer. We might consider that the feature parent of the three nested child components is simply a style component (maybe buttons or simple display elements). In this case, if there needed to be state or side effects, we would have those actions occur, through emits up the tree, and execute in the scripts of the feature parent “B” vs deeper down the tree. This approach limits the extent of side effects and keeps feature parent components smart and their child display components dumb, which makes maintenance easier.
Conclusion
Well, this was a long chapter but I hope some of the concepts came across. At the end of the day in the web engineering space, it’s going to be next to impossible to code purely functionally. However, it is possible to use functional programming ideas to make your JS code easier to test, less brittle, and less error-prone. We can do this through a thoughtful combination of declarative programming, reducing side effects, labeling impure functions, abstracting impure functions away from core business logic, and contextualizing your components and modules to enforce the separation of pure and impure functions.